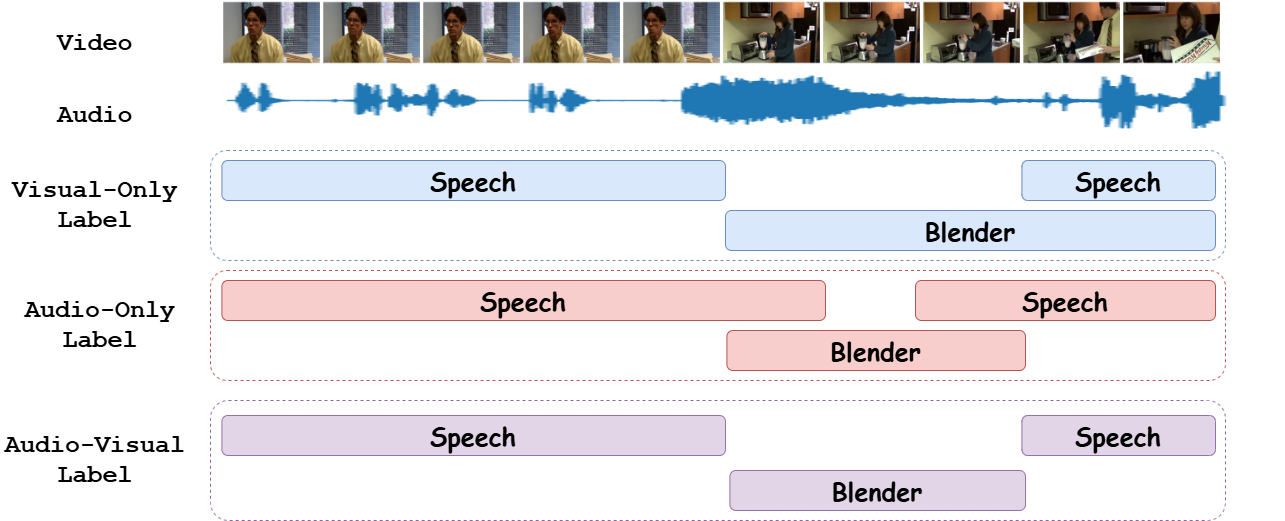
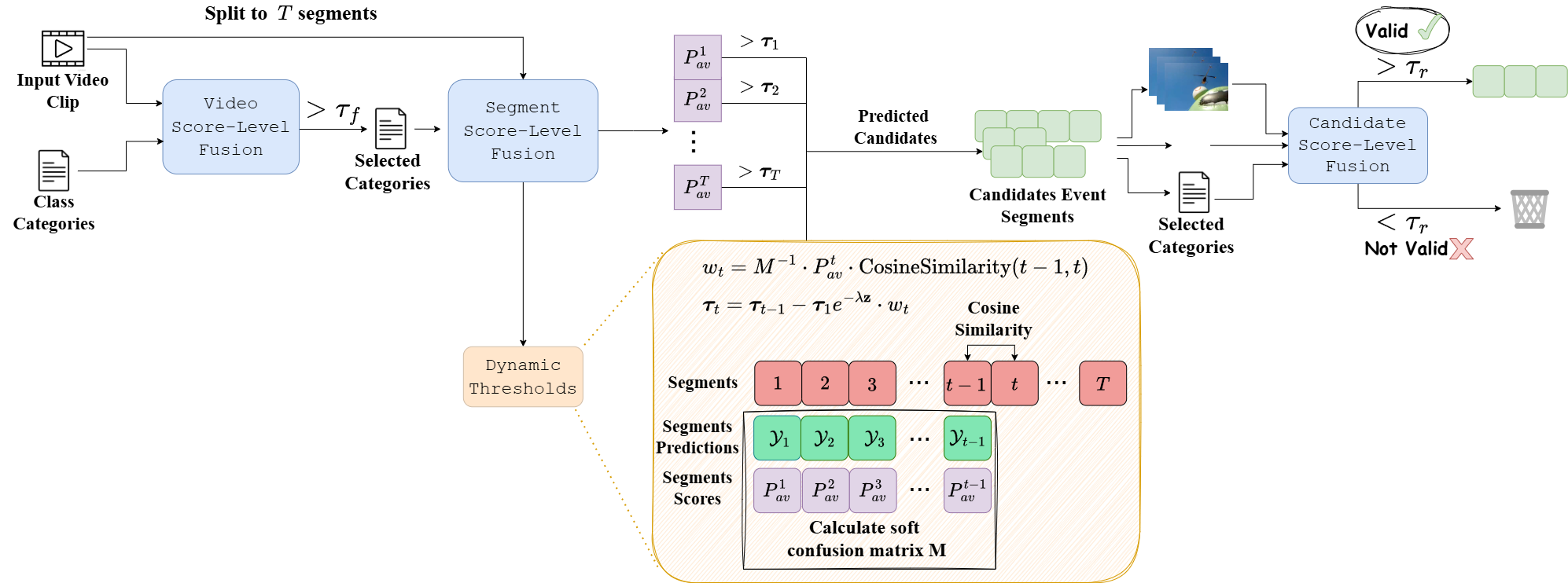
In the domain of audio-visual event perception, which focuses on the temporal localization and classification of events across distinct modalities (audio and visual), existing approaches are constrained by the vocabulary available in their training data. This limitation significantly impedes their capacity to generalize to novel, unseen event categories. Furthermore, the annotation process for this task is labor-intensive, requiring extensive manual labeling across modalities and temporal segments, limiting the scalability of current methods. Current state-of-the-art models ignore the shifts in event distributions over time, reducing their ability to adjust to changing video dynamics. Additionally, previous methods rely on late fusion to combine audio and visual information. While straightforward, this approach results in a significant loss of multimodal interactions.
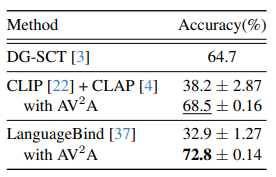
To address these challenges, we propose Audio-Visual Adaptive Video Analysis (AV²A), a model-agnostic approach that requires no further training and integrates an score-level fusion technique to retain richer multimodal interactions. AV²A also includes a within-video label shift algorithm, leveraging input video data and predictions from prior frames to dynamically adjust event distributions for subsequent frames. Moreover, we present the first training-free, open-vocabulary baseline for audio-visual event perception, demonstrating that AV²A achieves substantial improvements over naive training-free baselines. We demonstrate the effectiveness of AV²A on both zero-shot and weakly-supervised state-of-the-art methods, achieving notable improvements in performance metrics over existing approaches.